Przyszłość uczenia maszynowego
Od modeli statycznych do autonomicznych systemów uczących się w czasie rzeczywistym


Rozwój sztucznej inteligencji to historia ewolucji sposobów uczenia się maszyn, od algorytmów opartych na regułach, przez sieci neuronowe, aż po współczesne modele uczące się z danych. Początkowo AI opierała się na systemach eksperckich, w których wiedza była ręcznie kodowana przez ludzi w postaci reguł logicznych. Następnie, w latach 80. i 90., pojawiły się sieci neuronowe inspirowane biologicznym mózgiem, zdolne do rozpoznawania wzorców, ale ograniczone skalą i mocą obliczeniową. Przełom nastąpił wraz z rozwojem uczenia maszynowego: zamiast programować zachowanie, zaczęto trenować modele na dużych zbiorach danych. To podejście (szczególnie w wersji głębokiego uczenia tj. deep learning) umożliwiło powstanie systemów zdolnych do rozumienia języka, obrazu, dźwięku i działania w świecie. Dzisiejsza AI to już nie tylko algorytmy. To dynamiczne, uczące się struktury, które same odkrywają reguły, reprezentacje i strategie działania. Ta analiza pokazuje, dokąd zmierza ta ewolucja.
Zastrzeżenie
Niniejsza analiza stanowi próbę nakreślenia kierunków ewolucji systemów uczenia maszynowego w perspektywie krótko-, średnio- i długoterminowej. Treść opracowania opiera się na aktualnie obserwowanych sygnałach rynkowych oraz trendach technologicznych, takich jak dominacja modeli bazowych (foundation models) oraz rozwój autonomicznych agentów AI.
Sygnał
Rozwój sztucznej inteligencji wchodzi w fazę, w której dotychczasowe paradygmaty uczenia maszynowego przestają wystarczać. Modele nie tylko rosną w skali, lecz przede wszystkim zmieniają sposób, w jaki uczą się świata: od statycznych zbiorów danych przechodzą do dynamicznych, samo nadzorujących się procesów, zdolnych do adaptacji i działania w złożonych środowiskach. W nadchodzących latach kluczowe stanie się nie to, jak wiele danych posiadamy, lecz jak inteligentnie systemy potrafią je interpretować, generować i wykorzystywać. To właśnie ta transformacja wyznacza kierunek przyszłości uczenia maszynowego.
Innymi słowy:
Przyszłość sztucznej inteligencji to przejście od systemów, które sztywno odtwarzają dane przygotowane przez człowieka, do autonomicznych maszyn uczących się działania i rozumienia świata bezpośrednio z rzeczywistości w czasie rzeczywistym.

Analiza
Od nadzorowanego uczenia do ery „uczenia się z rzeczywistości”
Przez ostatnie dwie dekady królowało uczenie nadzorowane: ogromne zbiory danych, etykiety, klasyfikacja, regresja. To się nie skończy, ale jego rola będzie coraz bardziej „infrastrukturalna”, a nie przełomowa.
Coraz wyraźniej widać, że przyszłość należy do metod, które nie wymagają ręcznego etykietowania:
Uczenie samonadzorowane (self‑supervised learning)
Modele uczą się z samych danych, tworząc zadania pomocnicze: przewidują brakujące fragmenty tekstu, kolejne klatki w wideo, ukryte części obrazu. To właśnie ten paradygmat stoi za foundation models (duże modele językowe, modele multimodalne) i jest postrzegany jako „silnik” obecnej rewolucji generatywnej.
W przyszłości będzie on jeszcze bardziej dominujący, bo:
· pozwala wykorzystać praktycznie nieograniczone ilości surowych danych,
· umożliwia tworzenie uniwersalnych reprezentacji, które można dostosować do wielu zadań (fine‑tuning, promptowanie),
· zmniejsza koszt pozyskiwania danych (etykiety stają się dodatkiem, nie fundamentem).
Uczenie nienadzorowane i klastrowanie na sterydach
Klasyczne klastrowanie czy redukcja wymiaru nie znikną, ale będą wchłonięte przez bardziej złożone pipeline’y: modele będą same odkrywać struktury w danych, a dopiero potem człowiek będzie nadawał im znaczenie. W praktyce: mniej „ręcznego” projektowania cech, więcej automatycznego odkrywania struktur.
Uczenie z danych syntetycznych
Foundation models będą generować dane treningowe dla innych modeli: scenariusze rzadkich zdarzeń, skrajne przypadki, symulacje. To zmieni sposób myślenia o „zbiorze danych” – stanie się on dynamiczny, współtworzony przez inne modele, a nie tylko przez ludzi.
Foundation models jako nowa „warstwa operacyjna” AI
Kluczowy trend: duże, ogólne modele (językowe, wizualne, multimodalne) stają się platformą, na której buduje się kolejne systemy. To nie jest tylko kwestia skali, ale zmiany architektury całego ekosystemu.
Modele bazowe jako uniwersalne reprezentacje świata
Foundation models uczone samonadzorowanie na gigantycznych korpusach stają się „warstwą semantyczną” – przechowują wiedzę o języku, obrazach, kodzie, a coraz częściej także o dynamice świata (wideo, symulacje).
Przyszłe systemy uczenia maszynowego będą:
· rzadziej trenowane od zera,
· częściej budowane jako cienkie warstwy specjalizacji na wierzchu istniejących modeli,
· łączyć wiele foundation models (np. językowy + wizualny + model planowania).
Modele multimodalne jako standard
Granica między „modelem NLP”, „modelem do obrazów” a „modelem do sygnałów” będzie się zacierać. Przyszłe systemy będą:
· przyjmować tekst, obraz, dźwięk, wideo, dane sensoryczne,
· uczyć się wspólnych reprezentacji, co umożliwi przenoszenie wiedzy między modalnościami (np. uczysz się z tekstu, wykorzystujesz w wideo).
Modele specjalizowane na krawędzi (edge)
Równolegle do gigantów w chmurze będą rozwijane lekkie, wyspecjalizowane modele działające lokalnie: w telefonach, samochodach, robotach. Będą one:
korzystać z wiedzy foundation models (distillation, kompresja),
uczyć się dalej lokalnie (continual learning, federated learning),
działać w trybie offline, z naciskiem na prywatność i niskie opóźnienia.
Przyszłość uczenia ze wzmocnieniem: od laboratoriów do realnych systemów
Uczenie ze wzmocnieniem (RL) długo było „obietnicą przyszłości”: świetne wyniki w grach, trudności w realnym świecie. To się zmienia, zwłaszcza w połączeniu z foundation models.
Głębokie RL w erze foundation models
Coraz więcej prac łączy RL z dużymi modelami: modele językowe jako polityki, planery, generatory akcji; RL jako mechanizm dostrajania zachowania do celów i preferencji.
Przyszłe systemy będą:
· używać foundation models do rozumienia kontekstu i generowania planów,
· używać RL do optymalizacji decyzji w środowisku (robotyka, systemy rekomendacyjne, zarządzanie zasobami),
· łączyć symulacje, dane historyczne i interakcje w czasie rzeczywistym.
Model‑based RL i uczenie „światowych modeli”
Zamiast uczyć się tylko polityki („co robić”), systemy będą uczyć się modeli świata („co się stanie, jeśli…”). To umożliwi:
· planowanie w wyobraźni (imagination‑based planning),
· testowanie wielu scenariuszy bez ryzyka w realnym środowisku,
· lepsze wykorzystanie danych (sample efficiency).
RL z ludzką informacją zwrotną i preferencjami
Już dziś widać, jak RL z feedbackiem od człowieka (RLHF) kształtuje zachowanie dużych modeli.
W przyszłości:
preferencje użytkowników, normy społeczne, ograniczenia etyczne będą wbudowywane w proces uczenia,
pojawią się bardziej wyrafinowane formy feedbacku (nie tylko oceny binarne, ale złożone sygnały, np. z interakcji długoterminowych).
Uczenie ciągłe, adaptacyjne i „żyjące” systemy
Klasyczny paradygmat: zbiór danych → trening → wdrożenie → koniec. Przyszłość: systemy, które uczą się przez cały cykl życia.
Continual learning
Modele będą:
· aktualizować się na bieżąco, bez pełnego retrainingu,
· radzić sobie z katastrofalnym zapominaniem (mechanizmy pamięci, architektury modularne),
· utrzymywać „historię doświadczeń”, z której można wracać do wcześniejszych stanów.
Uczenie w strumieniu danych (online learning)
W wielu zastosowaniach (finanse, cyberbezpieczeństwo, IoT, personalizacja) dane są strumieniem, a nie statycznym zbiorem. Przyszłe systemy:
· będą reagować na zmiany rozkładów danych (concept drift),
· dynamicznie dostosowywać swoje parametry i strategie.
Modele, które same zarządzają swoim uczeniem
Pojawi się coraz więcej meta‑uczenia: systemy będą:
wybierać, z jakich danych się uczyć (active learning),
decydować, jakie zadania pomocnicze tworzyć (automatyczne pretext tasks w self‑supervised learning),
optymalizować własną architekturę i hiperparametry (AutoML na sterydach).
Federated learning, prywatność i rozproszone uczenie
Wraz z rosnącą wrażliwością na prywatność i regulacje, przyszłość uczenia maszynowego będzie coraz bardziej rozproszona.
Uczenie federacyjne
Dane pozostają na urządzeniach użytkowników, a do chmury trafiają tylko zaktualizowane parametry modeli. To podejście:
· pozwala trenować na wrażliwych danych (medycyna, finanse, urządzenia osobiste),
· zmniejsza ryzyko wycieku danych,
· wymaga nowych metod radzenia sobie z heterogenicznością danych i urządzeń.
Prywatność różnicowa i bezpieczeństwo modeli
Metody zapewniające formalne gwarancje prywatności (np. dodawanie kontrolowanego szumu) będą coraz częściej wbudowane w pipeline’y uczenia. Równolegle:
rozwijać się będą techniki obrony przed atakami na modele (poisoning, model extraction),
pojawią się standardy audytu modeli pod kątem prywatności i bezpieczeństwa.
Causal ML, neurosymboliczne podejścia i „rozumienie” świata
Kolejny kierunek: odejście od czystej korelacji w stronę przyczynowości i struktur symbolicznych.
Uczenie przyczynowe (causal ML)
Modele przyszłości będą:
· rozróżniać korelacje od relacji przyczynowych („co się stanie, jeśli zmienię X?”),
· lepiej generalizować poza rozkład treningowy (out‑of‑distribution),
· wspierać decyzje w dziedzinach, gdzie liczy się zrozumienie mechanizmów (medycyna, polityka publiczna, ekonomia).
Neurosymboliczne systemy
Połączenie sieci neuronowych (percepcja, reprezentacje) z logiką i strukturami symbolicznymi (reguły, wiedza dziedzinowa) pozwoli:
lepiej wyjaśniać decyzje modeli,
wprowadzać twarde ograniczenia (np. prawa fizyki, reguły biznesowe),
budować systemy, które potrafią zarówno „widzieć”, jak i „wnioskować”.
Metody uczenia w przyszłości – syntetyczne podsumowanie
Jeśli spróbujemy nazwać główne klasy metod, które będą kształtować przyszłość uczenia maszynowego, to lista wygląda mniej więcej tak:
Uczenie samonadzorowane i foundation models jako główny sposób pozyskiwania reprezentacji świata.
Uczenie ze wzmocnieniem (szczególnie model‑based, z feedbackiem od ludzi) jako mechanizm uczenia się działania i podejmowania decyzji.
Uczenie ciągłe, online, federacyjne jako odpowiedź na dynamiczne, rozproszone i wrażliwe środowiska danych.
Metody przyczynowe i neurosymboliczne jako krok w stronę głębszego rozumienia i wyjaśnialności.
Meta‑uczenie i AutoML jako sposób na automatyzację samego procesu uczenia i projektowania modeli.
Wnioski
Wnioski krótkoterminowe (1–2 lata)
Dominacja foundation models i metod samonadzorowanych jako podstawowego standardu uczenia.
Odejście od trenowania modeli od zera na rzecz dostrajania istniejących architektur.
Rosnące znaczenie prywatności, bezpieczeństwa i zgodności regulacyjnej w procesach uczenia.
Uczenie ze wzmocnieniem stosowane głównie jako narzędzie do kształtowania zachowania modeli.
Szybkie wdrażanie lekkich modeli na urządzeniach końcowych (edge AI).
Wnioski średnioterminowe (3–6 lat)
Przejście do systemów uczących się w sposób ciągły i adaptacyjny (continual learning).
Upowszechnienie uczenia federacyjnego w środowiskach rozproszonych i wrażliwych na prywatność.
Integracja percepcji, planowania i działania w ramach jednego modelu lub zestawu modeli.
Dojrzewanie metod przyczynowych i neurosymbolicznych jako sposobu na lepszą interpretowalność.
Wzrost znaczenia meta‑uczenia i automatyzacji procesu trenowania (AutoML).
Wnioski długoterminowe (7+ lat)
Powstanie ekosystemu autonomicznych, samodzielnie uczących się systemów zdolnych do generowania własnych danych.
Zacieranie granic między różnymi paradygmatami uczenia — dominacja podejść hybrydowych.
Rozwój modeli świata i uczenia przyczynowego jako fundamentu zaawansowanego rozumowania.
AI staje się partnerem decyzyjnym, a nie tylko narzędziem analitycznym.
Konieczność stworzenia nowych ram etycznych, regulacyjnych i technicznych dla systemów o wysokim poziomie autonomii.
Rekomendacje strategiczne
Wzmocnić kompetencje w obszarze foundation models i samonadzorowanego uczenia
Budować kompetencje w pracy z dużymi modelami bazowymi zamiast inwestować w trenowanie modeli od zera.
Rozwijać umiejętności dostrajania (fine‑tuning, prompt engineering, RAG), bo to będzie dominujący sposób tworzenia rozwiązań AI.
Monitorować tempo rozwoju multimodalnych modeli, które staną się standardem w większości zastosowań.
Przygotować organizację na przejście do systemów adaptacyjnych
Projektować architektury AI z myślą o ciągłym uczeniu (continual learning) i aktualizacji modeli w cyklu życia produktu.
Wprowadzać procesy monitorowania jakości danych i zmian rozkładów (concept drift), aby modele pozostawały stabilne w czasie.
Budować pipeline’y, które umożliwiają szybkie iteracje i automatyczne dostrajanie modeli.
Inwestować w prywatność, bezpieczeństwo i zgodność regulacyjną
Wdrażać mechanizmy prywatności różnicowej, uczenia federacyjnego i kontrolowanego dostępu do danych.
Tworzyć procedury audytu modeli pod kątem bezpieczeństwa, odporności na ataki i zgodności z regulacjami.
Zapewnić, aby procesy uczenia były transparentne i możliwe do wyjaśnienia dla interesariuszy.
Rozwijać kompetencje w obszarze uczenia ze wzmocnieniem i modeli świata
Eksperymentować z RL w obszarach, gdzie decyzje mają charakter sekwencyjny (logistyka, optymalizacja, robotyka, rekomendacje).
Łączyć RL z foundation models, aby tworzyć systemy zdolne do planowania i działania w złożonych środowiskach.
Budować prototypy oparte na model‑based RL, które umożliwiają symulowanie scenariuszy i testowanie strategii bez ryzyka.
Przygotować się na integrację metod przyczynowych i neurosymbolicznych
Wprowadzać narzędzia causal ML w obszarach, gdzie kluczowe jest rozumienie mechanizmów, a nie tylko korelacji.
Łączyć modele neuronowe z regułami symbolicznymi, aby zwiększyć interpretowalność i kontrolę nad systemami.
Budować zespoły, które potrafią pracować zarówno z danymi statystycznymi, jak i wiedzą ekspercką.
Budować architekturę danych i procesy pod przyszłe wymagania AI
Zaprojektować spójne środowisko danych, które umożliwia trenowanie, aktualizację i monitorowanie modeli w sposób ciągły.
Wprowadzić standardy jakości danych, bo foundation models i systemy adaptacyjne są szczególnie wrażliwe na ich jakość.
Zapewnić skalowalną infrastrukturę obliczeniową, która obsłuży zarówno modele w chmurze, jak i lekkie modele na urządzeniach końcowych.
Przygotować organizację na rosnącą autonomię systemów AI
Opracować zasady odpowiedzialnego wdrażania systemów autonomicznych, w tym ramy etyczne i procesy nadzoru.
Wprowadzić mechanizmy kontroli, które pozwalają na interwencję człowieka w krytycznych momentach.
Edukować zespoły w zakresie pracy z agentami AI, którzy będą działać bardziej samodzielnie niż dotychczasowe modele.
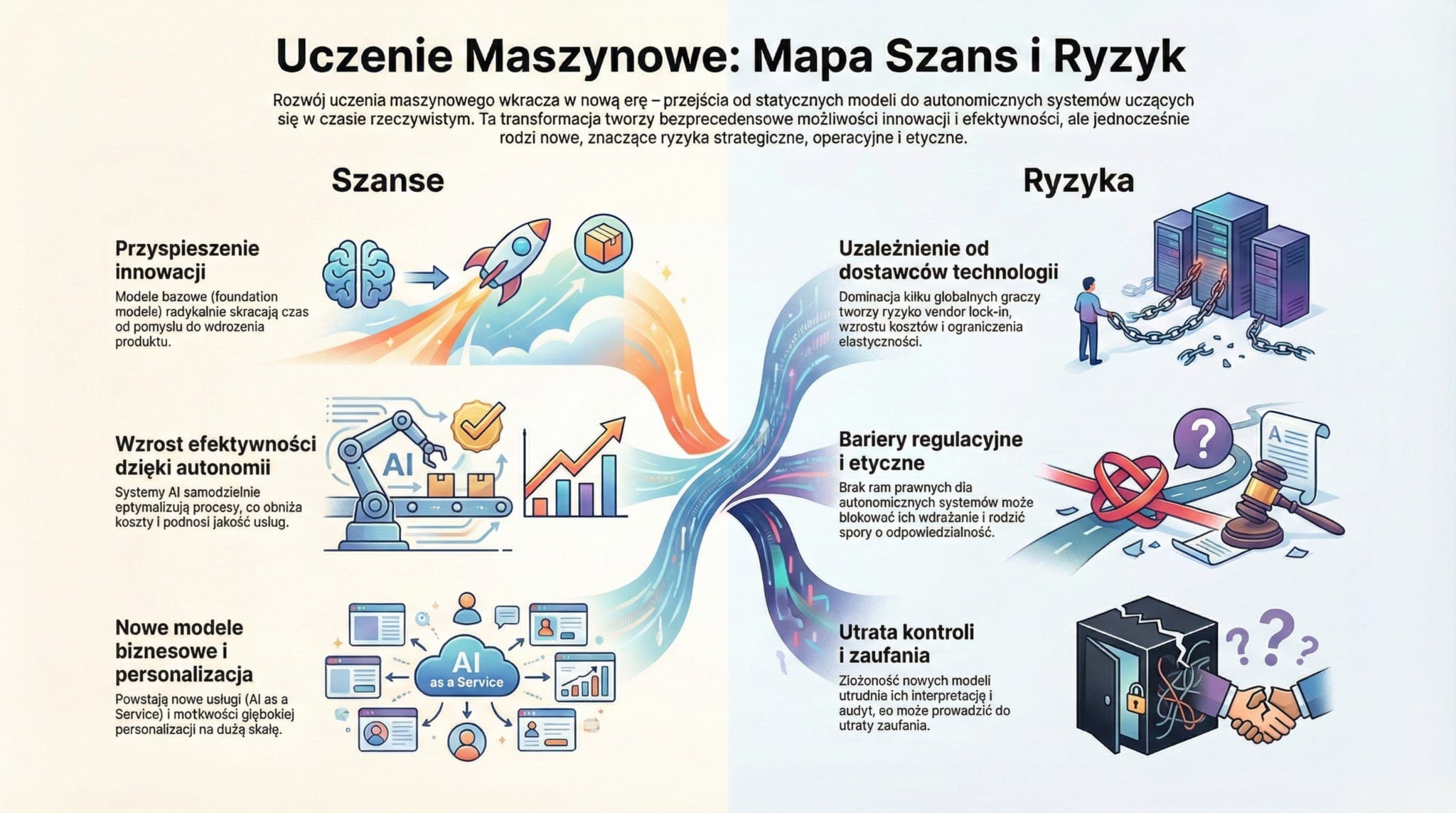
Mapa ryzyk i szans rozwoju systemów uczenia maszynowego
Szanse (Opportunities)
Skalowalność i przyspieszenie innowacji
Foundation models umożliwiają szybkie tworzenie nowych rozwiązań bez konieczności trenowania modeli od zera.
Organizacje mogą znacznie skrócić czas od pomysłu do wdrożenia, co zwiększa przewagę konkurencyjną.
Autonomiczne systemy zwiększające efektywność
Uczenie ciągłe, RL i modele świata otwierają drogę do systemów, które samodzielnie optymalizują procesy.
Automatyzacja zadań decyzyjnych i operacyjnych może radykalnie obniżyć koszty i poprawić jakość usług.
Nowe możliwości personalizacji
Modele adaptacyjne i federacyjne pozwalają tworzyć rozwiązania dopasowane do indywidualnych użytkowników bez naruszania prywatności.
Personalizacja w czasie rzeczywistym stanie się standardem w produktach cyfrowych.
Lepsze rozumienie złożonych zjawisk
Metody przyczynowe i neurosymboliczne umożliwią bardziej wiarygodne analizy i decyzje w obszarach takich jak medycyna, finanse czy polityki publiczne.
Modele będą potrafiły nie tylko przewidywać, ale także wyjaśniać mechanizmy.
Rozwój nowych modeli biznesowych
AI jako usługa, agentowe systemy wykonawcze, symulacje oparte na modelach świata — to nowe przestrzenie monetyzacji.
Firmy mogą tworzyć produkty, które wcześniej były technologicznie niemożliwe.
Ryzyka (Risks)
Uzależnienie od dostawców technologii
Dominacja kilku globalnych dostawców foundation models może prowadzić do koncentracji ryzyka, ograniczenia elastyczności i wzrostu kosztów.
Brak kompetencji wewnętrznych zwiększa podatność na vendor lock‑in.
Ryzyka związane z jakością danych
Modele adaptacyjne są wrażliwe na błędy, uprzedzenia i zmiany w danych.
Concept drift może prowadzić do nieprzewidywalnych zachowań modeli, jeśli nie ma odpowiednich mechanizmów monitorowania.
Rosnące wymagania regulacyjne i etyczne
Systemy autonomiczne będą wymagały nowych ram prawnych, a ich brak może blokować wdrożenia.
Ryzyko naruszeń prywatności i odpowiedzialności za decyzje AI będzie rosło wraz z poziomem autonomii.
Ataki na modele i infrastruktury AI
Modele mogą być podatne na ataki typu poisoning, model extraction czy adversarial examples.
Wraz z rosnącą autonomią rośnie też powierzchnia ataku.
Trudności w interpretacji i kontroli systemów
Hybrydowe modele łączące percepcję, planowanie i działanie mogą być trudne do audytowania.
Brak przejrzystości może prowadzić do utraty zaufania użytkowników i regulatorów.
Konkluzja
Rozwój uczenia maszynowego otwiera ogromne możliwości — od autonomicznych systemów po głęboką personalizację i nowe modele biznesowe. Jednocześnie rośnie skala ryzyk: technicznych, regulacyjnych, operacyjnych i etycznych. Kluczowe będzie budowanie kompetencji, które pozwolą organizacjom wykorzystać szanse, jednocześnie minimalizując zagrożenia.
Implikacje
Implikacje dla Państwa
Konieczność stworzenia nowoczesnych ram regulacyjnych, które nadążą za tempem rozwoju AI, jednocześnie nie blokując innowacji.
Wzrost znaczenia nadzoru nad bezpieczeństwem danych, prywatnością i odpowiedzialnością za decyzje systemów autonomicznych.
Potrzeba inwestycji w infrastrukturę cyfrową, superkomputery, krajowe modele językowe i kompetencje administracji publicznej.
Wymóg budowania zdolności do audytu i certyfikacji systemów AI, zwłaszcza w sektorach krytycznych (zdrowie, transport, energetyka).
Rosnąca rola państwa jako regulatora, ale też użytkownika AI — w usługach publicznych, analizie danych i bezpieczeństwie.
Implikacje dla biznesu (producentów oprogramowania i systemów AI)
Konieczność przejścia z modeli tworzonych od zera na architektury oparte na foundation models i multimodalności.
Wzrost znaczenia kompetencji w zakresie fine‑tuning, RAG, RLHF, modeli świata i systemów agentowych.
Potrzeba budowania rozwiązań zgodnych z regulacjami, audytowalnych i transparentnych — to stanie się przewagą konkurencyjną.
Konieczność inwestowania w bezpieczeństwo modeli (odporność na ataki, kontrola danych treningowych, monitoring zachowania).
Rosnące oczekiwania klientów dotyczące personalizacji, adaptacyjności i integracji AI z istniejącymi procesami biznesowymi.
Wymóg tworzenia systemów, które potrafią działać zarówno w chmurze, jak i na urządzeniach końcowych (edge AI).
Implikacje dla biznesu (użytkowników rozwiązań AI)
Możliwość radykalnego zwiększenia efektywności operacyjnej dzięki automatyzacji, predykcji i systemom decyzyjnym opartym na AI.
Konieczność przebudowy procesów biznesowych, aby w pełni wykorzystać potencjał systemów adaptacyjnych i agentowych.
Wzrost znaczenia jakości danych — firmy będą musiały inwestować w ich porządkowanie, standaryzację i governance.
Potrzeba rozwijania kompetencji pracowników w zakresie współpracy z AI, interpretacji wyników i nadzoru nad systemami.
Ryzyko uzależnienia od dostawców technologii — konieczność budowania minimalnych kompetencji wewnętrznych, aby zachować kontrolę.
Wymóg ciągłego monitorowania modeli, bo ich zachowanie będzie zmieniać się wraz z danymi i środowiskiem.
Implikacje dla „Kowalskiego”
Coraz większa obecność AI w codziennym życiu — od usług publicznych, przez pracę, po narzędzia osobiste.
Wzrost znaczenia kompetencji cyfrowych i umiejętności współpracy z systemami AI, które staną się naturalnym elementem pracy.
Możliwość korzystania z bardziej spersonalizowanych usług, lepszej opieki zdrowotnej, inteligentnych asystentów i automatyzacji codziennych zadań.
Ryzyko dezinformacji, manipulacji i utraty prywatności — konieczność świadomego korzystania z technologii.
Zmiany na rynku pracy: część zadań zostanie zautomatyzowana, ale pojawią się nowe role związane z nadzorem, interpretacją i współpracą z AI.
Większa odpowiedzialność za zarządzanie własnymi danymi i zrozumienie, jak systemy AI wpływają na decyzje dotyczące jednostki.
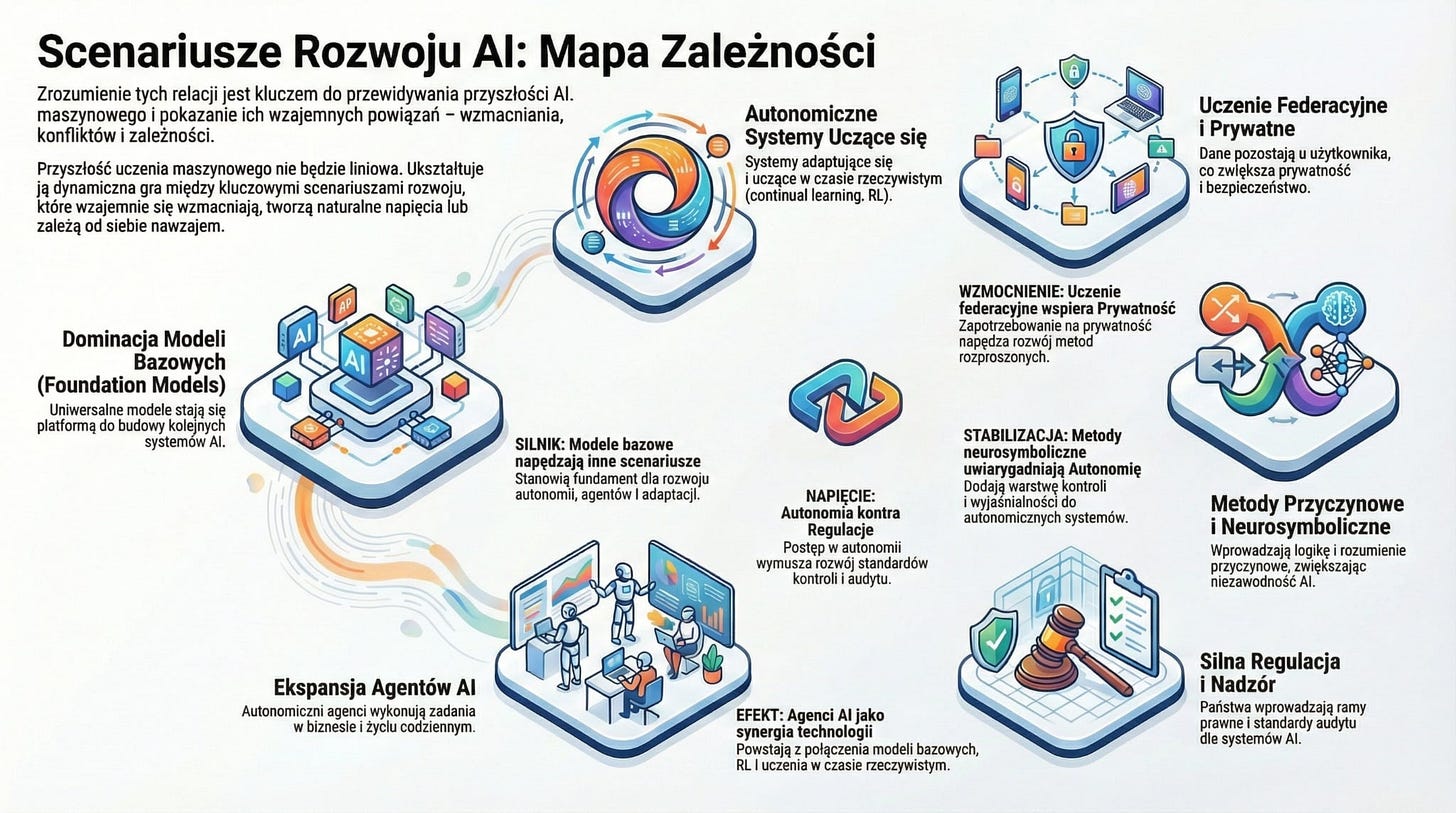
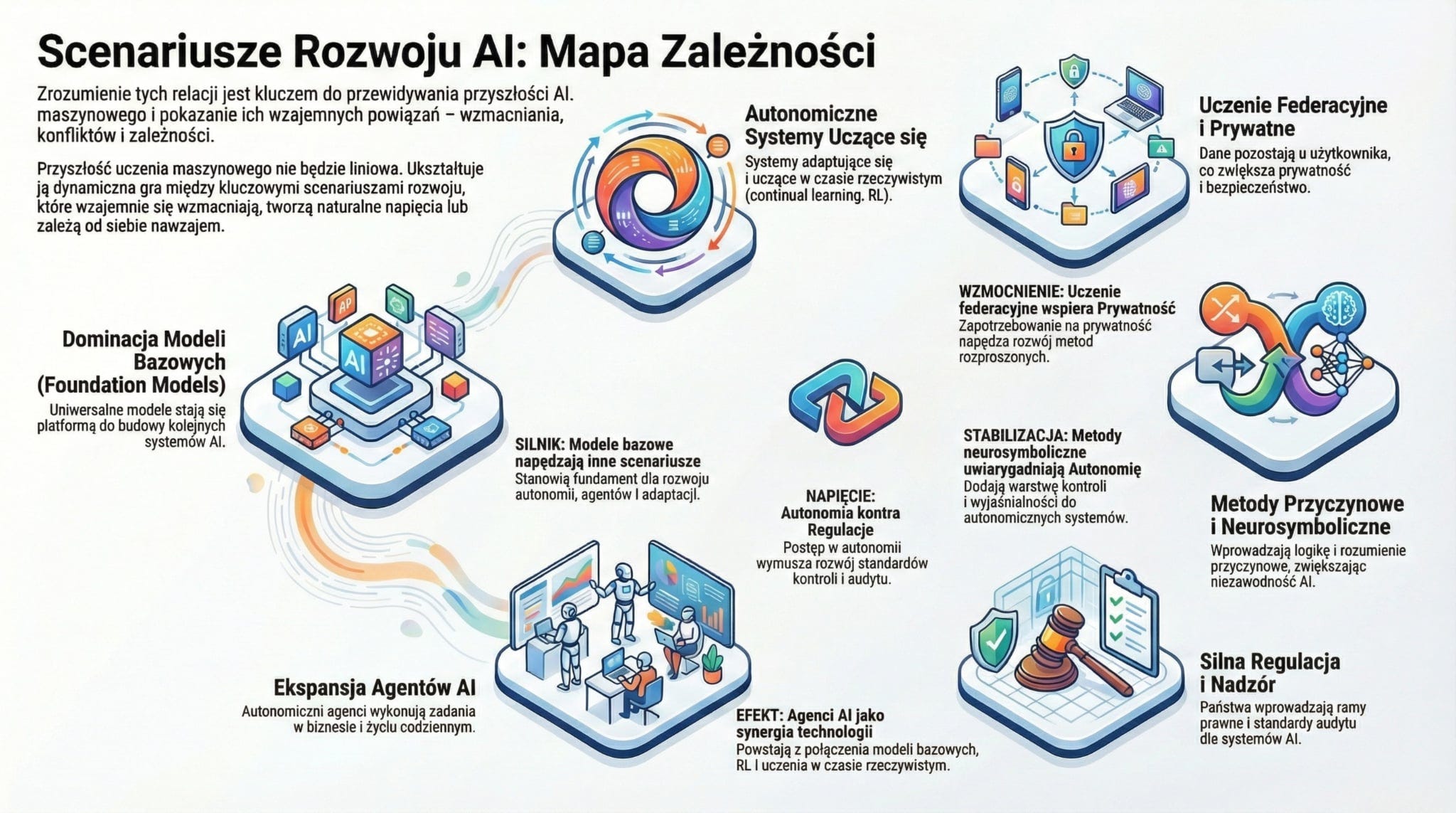
Mapa scenariuszy rozwoju systemów ucznia maszynowego
Scenariusz: Dominacja foundation models i multimodalnych systemów bazowych
Powiązania z innymi scenariuszami:
Wzmacnia rozwój autonomicznych agentów, bo dostarcza im uniwersalnych reprezentacji świata.
Przyspiesza przejście do uczenia ciągłego i adaptacyjnego, bo modele bazowe stają się platformą do dalszego uczenia.
Wymusza rozwój regulacji i standardów audytu, co łączy się ze scenariuszem rosnącej roli państwa.
Ogranicza scenariusz pełnej decentralizacji, bo koncentracja mocy obliczeniowej sprzyja dużym graczom.
Scenariusz: Autonomiczne systemy uczące się w czasie rzeczywistym (continual learning + RL + modele świata)
Powiązania:
Silnie zależy od foundation models, które dostarczają bazowej wiedzy i percepcji.
Wspiera rozwój edge AI, bo systemy autonomiczne muszą działać lokalnie i nisko‑opóźnieniowo.
Wchodzi w konflikt z regulacjami wymagającymi pełnej audytowalności — adaptacyjne modele trudniej kontrolować.
Wzmacnia scenariusz nowych modeli biznesowych opartych na agentach wykonawczych.
Scenariusz: Federacyjne, prywatne i rozproszone uczenie maszynowe
Powiązania:
Łagodzi ryzyka koncentracji technologicznej wynikające z dominacji foundation models.
Wspiera scenariusz personalizacji usług, bo dane pozostają u użytkownika.
Może ograniczać rozwój autonomicznych agentów, jeśli regulacje utrudnią wymianę danych między urządzeniami.
Wzmacnia scenariusz rosnącej roli państwa w nadzorze nad prywatnością i bezpieczeństwem.
Scenariusz: Integracja metod przyczynowych i neurosymbolicznych
Powiązania:
Stabilizuje scenariusz autonomicznych systemów, bo wprowadza większą interpretowalność i kontrolę.
Wspiera foundation models, dodając im warstwę logiczną i przyczynową, co poprawia ich niezawodność.
Może spowolnić rozwój adaptacyjnych modeli, jeśli nacisk na wyjaśnialność ograniczy swobodę uczenia.
Zwiększa akceptację społeczną AI, co wzmacnia scenariusz szerokiej adopcji w sektorze publicznym.
Scenariusz: Silna regulacja i państwowy nadzór nad AI
Powiązania:
Wzmacnia scenariusz neurosymboliczny i przyczynowy, bo te metody są bardziej audytowalne.
Może ograniczać tempo rozwoju autonomicznych agentów i adaptacyjnych modeli.
Zwiększa zapotrzebowanie na federacyjne i prywatne uczenie.
Może osłabić dominację globalnych foundation models, jeśli państwa zaczną budować własne modele narodowe.
Scenariusz: Ekspansja agentów AI w biznesie i życiu codziennym
Powiązania:
Silnie zależy od foundation models i uczenia ze wzmocnieniem.
Wzmacnia scenariusz adaptacyjnych systemów uczących się w czasie rzeczywistym.
Może kolidować z regulacjami, jeśli poziom autonomii przekroczy akceptowalne normy.
Przyspiesza rozwój edge AI, bo agenci muszą działać blisko użytkownika.
Syntetyczna mapa zależności
Foundation models → są „silnikiem” większości pozostałych scenariuszy.
Autonomia i adaptacja ↔ Regulacje i audyt → relacja napięcia: rozwój jednego wymusza zmiany w drugim.
Federacyjne uczenie ↔ Prywatność i państwowy nadzór → wzajemne wzmacnianie.
Neurosymboliczne i przyczynowe podejścia → stabilizują i uwiarygadniają scenariusze wysokiej autonomii.
Agenci AI → są końcowym efektem synergii foundation models, RL, modeli świata i edge AI.
Konkluzja
Przyszłość uczenia maszynowego nie będzie liniowa. Będzie wynikiem dynamicznej gry między sześcioma głównymi scenariuszami. Niektóre z nich wzajemnie się wzmacniają (foundation models + autonomia + agenci), inne tworzą naturalne napięcia (autonomia vs regulacje). Zrozumienie tych zależności pozwala przewidywać, które kierunki rozwoju będą najbardziej prawdopodobne i jakie decyzje strategiczne warto podejmować już dziś.
Podsumowanie
Cała analiza pokazuje, że rozwój systemów uczenia maszynowego wchodzi w etap głębokiej transformacji, w którym dotychczasowe paradygmaty przestają wystarczać. Foundation models i metody samonadzorowane stają się nową warstwą infrastrukturalną, na której budowane będą kolejne generacje systemów AI. Równolegle rośnie znaczenie autonomii: uczenie ciągłe, modele świata i uczenie ze wzmocnieniem otwierają drogę do systemów zdolnych do samodzielnego działania i adaptacji. Jednocześnie coraz większą rolę odgrywają kwestie prywatności, bezpieczeństwa i regulacji, które będą kształtować tempo i kierunek wdrożeń. W perspektywie średnioterminowej kluczowe stanie się łączenie różnych metod — od neurosymbolicznych po przyczynowe — aby zwiększyć interpretowalność i stabilność modeli. W dłuższym horyzoncie możemy spodziewać się ekosystemu inteligentnych agentów, którzy będą współdziałać z ludźmi i innymi systemami w sposób bardziej autonomiczny niż dziś. Ta przyszłość niesie zarówno ogromne szanse, jak i istotne ryzyka, dlatego kluczowe będzie świadome zarządzanie rozwojem AI na poziomie państw, biznesu i społeczeństwa.
Co to oznacza?
Sztuczna inteligencja przestaje być tylko narzędziem wykonującym proste polecenia, a staje się samodzielnie uczącym się asystentem, który rozumie otoczenie i potrafi podejmować własne decyzje, co wymaga od nas mądrego ustalenia zasad jej działania, aby była bezpieczna i pomocna.
Czy chciałbyś, abym wyjaśnił prościej, co konkretnie zmieni się w Twoim otoczeniu w ciągu najbliższych kilku lat?
Co warto zapamiętać:
Trendy przyszłości uczenia maszynowego
Od danych do działania: maszyny przestają jedynie przetwarzać przygotowane przez ludzi bazy danych, a zaczynają samodzielnie uczyć się rozumienia świata i działania bezpośrednio w rzeczywistości.
Fundamenty i agenci: duże, uniwersalne modele bazowe stają się nową infrastrukturą, na której budowane są inteligentne systemy agentowe współpracujące z ludźmi w codziennych zadaniach.
Bezpieczna autonomia: wzrost samodzielności AI wymusza łączenie technologii z twardymi zasadami etyki, prywatności i logiki, aby systemy były przewidywalne i bezpieczne dla społeczeństwa.