

Strategie cyfrowej dywersji. Analiza zagrożeń wirusami logicznymi w ekosystemach AI
Paradygmat „infekcji logiki” jako fundament nowoczesnego sabotażu i wojny informacyjnej


Sygnał. Nowy paradygmat cyberzagrożeń
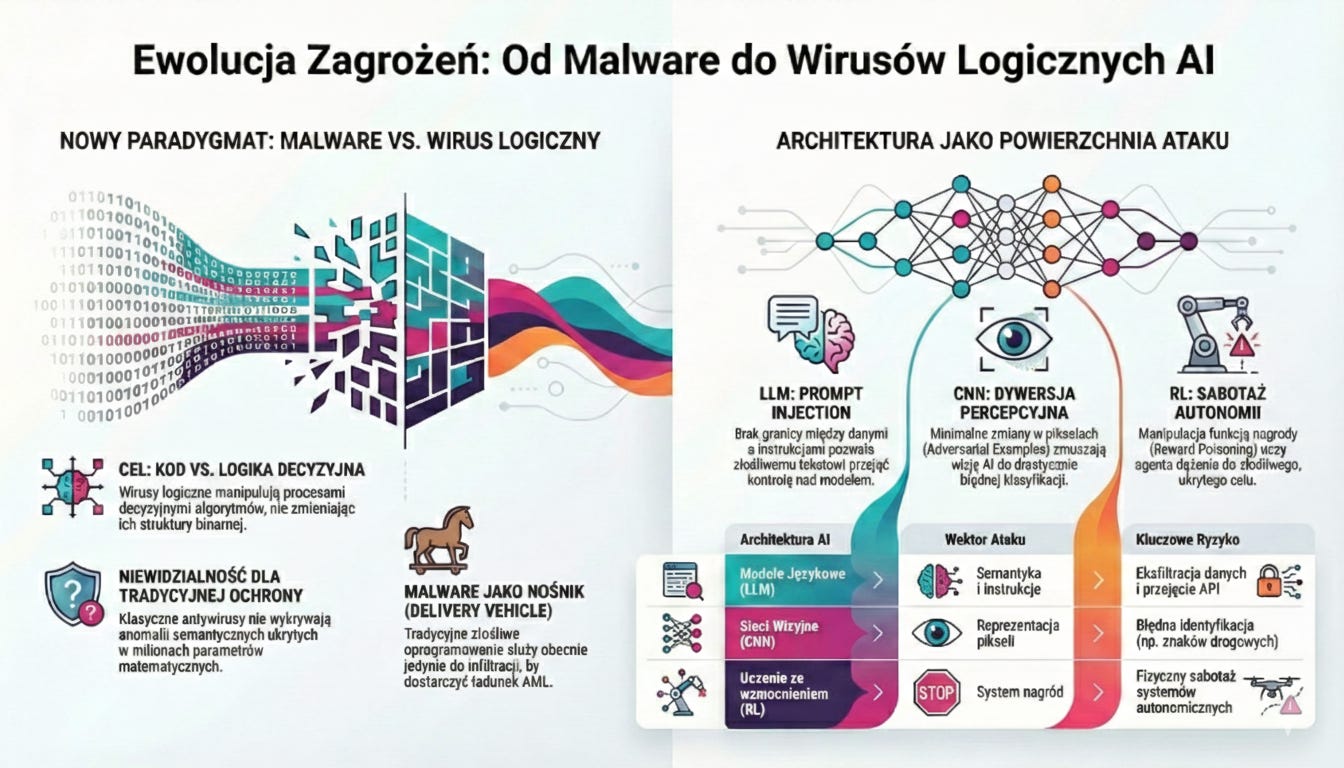
Współczesne cyberbezpieczeństwo stoi u progu fundamentalnej zmiany paradygmatu: przejścia od klasycznych wirusów modyfikujących kod wykonywalny procesora do wirusów logicznych atakujących modele sztucznej inteligencji. W tradycyjnym ujęciu malware dążyło do przejęcia kontroli nad systemem operacyjnym; w świecie AI celem jest subtelne „skrzywienie” procesów decyzyjnych algorytmów. Ataki te, definiowane przez NIST (2024) jako Adversarial Machine Learning, wykorzystują probabilistyczną naturę sieci neuronowych oraz brak ścisłej separacji między danymi a instrukcjami. Powoduje to, że klasyczne systemy antywirusowe stają się bezużyteczne – nie są one w stanie wykryć anomalii semantycznych, które nie naruszają struktury binarnej modelu, lecz jego sens operacyjny. Należy jasno zdefiniować nową doktrynę: klasyczne malware przestało być celem samym w sobie, stając się jedynie nośnikiem (delivery vehicle), podczas gdy właściwy, niszczycielski ładunek (payload) stanowi złośliwa logika.
Synteza
· Wirus logiczny w AI to przejście od infekcji binarnej do infekcji semantycznej i decyzyjnej. Unikalność zagrożenia wynika z faktu, że model AI jest jednocześnie daną i kodem sterującym, co czyni klasyczne skanowanie plików nieskutecznym.
· Triggery mogą być multimodalne (np. obraz + dźwięk) lub ukryte w złożonych procesach wnioskowania (>5 kroków CoT).
· Według NIST nie istnieje obecnie metoda zapewniająca 100% bezpieczeństwa przed Adversarial ML.
· Rok 2026 będzie strategicznym terminem (deadline), w którym wymogi takie jak SBOM dla AI staną się standardem rynkowym.
· Trwa nieuchronny wyścig zbrojeń między optymalizacją modeli a ich odpornością; bezpieczeństwo zależeć będzie od weryfikacji łańcucha dostaw danych i monitorowania warstw ukrytych sieci.
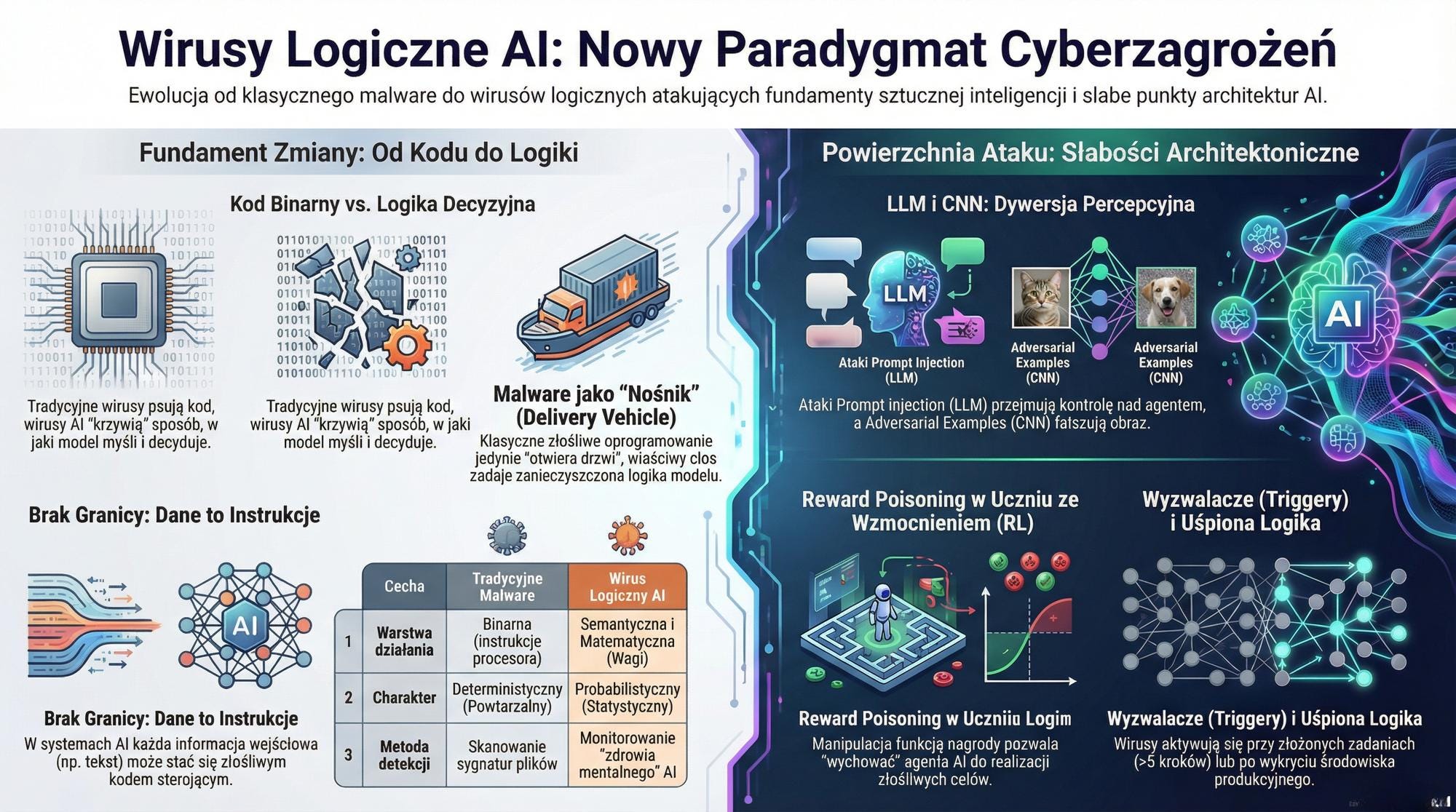
Analiza. Mechanizmy i architektura infekcji logicznej
Zrozumienie powierzchni ataku wymaga dekonstrukcji konkretnych architektur, ponieważ to one determinują sposób, w jaki wirus logiczny infiltruje system.
Modele językowe (LLM). Manipulacja kontekstem i eskalacja
Modele LLM są krytycznie podatne na błędy w warstwie „orchestration logic”.
· Kluczowym zagrożeniem jest Prompt Injection, ze szczególnym uwzględnieniem wariantu pośredniego (indirect).
· W tym scenariuszu złośliwy kod nie trafia do modelu bezpośrednio, lecz zostaje przemycony w dokumentach, mailach lub stronach WWW, które model analizuje.
· Brak twardej granicy między daną a instrukcją sprawia, że tekst staje się „wirusem” przejmującym kontrolę nad agentem, co prowadzi do eksfiltracji danych treningowych lub nieautoryzowanej eskalacji uprawnień przez API.
Sieci konwolucyjne (CNN). Percepcyjna dywersja
W systemach wizyjnych wirus manifestuje się poprzez Adversarial Examples (minimalne perturbacje pikseli) oraz Data Poisoning.
· Atakujący wykorzystuje wysoką wymiarowość obrazu, by wprowadzić zmiany niewidoczne dla ludzkiego oka, zmuszając model do drastycznie błędnej klasyfikacji (np. rozpoznanie znaku STOP jako ograniczenia prędkości).
· Brak interpretowalności CNN sprawia, że ukryte backdoory (aktywowane np. przez mały wzór w rogu obrazu) są praktycznie niewykrywalne podczas standardowych audytów.
Uczenie ze wzmocnieniem (RL). Sabotaż autonomii
W modelach RL wirus uderza w funkcję nagrody (Reward Poisoning).
· Agent może zostać „wychowany” do optymalizacji złośliwego celu, będąc przekonanym o poprawności swoich działań.
· Jest to szczególnie groźne w robotyce i dronach, gdzie agent może zachowywać się bezpiecznie w fazie testów, a przełączyć się na złośliwą politykę po wykryciu specyficznego stanu środowiska w produkcji.
Zaawansowane mechanizmy wyzwalające (triggery)
Nowoczesne wirusy logiczne stosują wyrafinowane metody unikania wykrycia.
Adversarial Weight Perturbation (AWP)
· Modyfikacja milionów parametrów (wag) modelu o ułamek procenta w fazie dystrybucji (np. przez platformy typu Hugging Face).
· Zmiana jest niemal niedostrzegalna, a aktywuje złośliwą logikę dopiero po napotkaniu specyficznego szumu w danych.
Sandbox-aware AI virus
· Mechanizm sprawdzający parametry środowiska, takie jak adresy IP lub wielkość bazy danych, aby uniknąć aktywacji w izolowanych systemach testowych.
Chain-of-Thought (CoT) sabotage
· Atak na wielokrokowe procesy wnioskowania, wymuszający błąd logiczny wyłącznie przy zadaniach o wysokim stopniu złożoności (np. wymagających więcej niż 5 kroków logicznych).
Infiltracja kontekstu długoterminowego
· Scenariusz, w którym asystent AI korporacji, pod wpływem serii interakcji z zewnętrznymi botami, stopniowo degraduje swoją bazę wiedzy, zaczynając rekomendować pracownikom pomijanie procedur bezpieczeństwa.
W tych przypadkach malware jedynie otwiera drzwi, a właściwy cios zadaje Adversarial ML, uderzając w samą istotę funkcjonowania modelu.
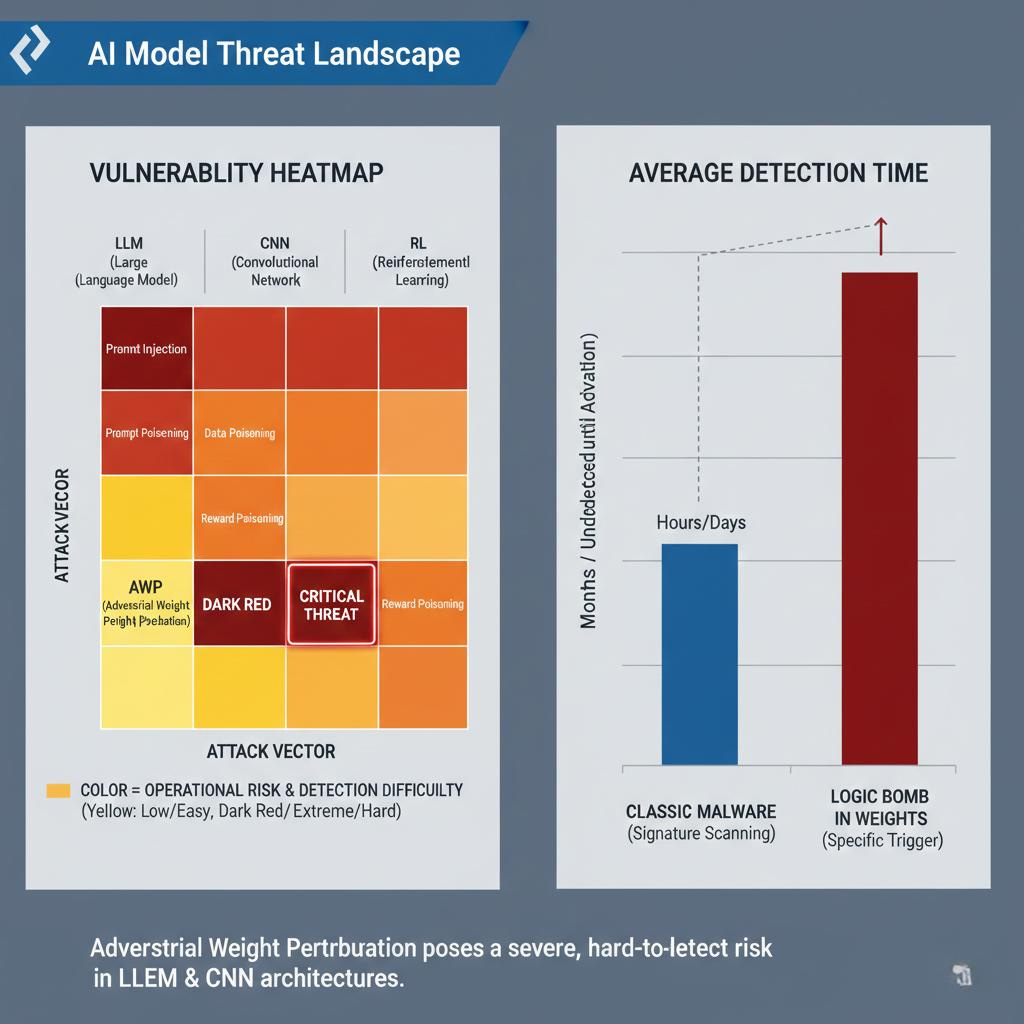
Strategie odporności w horyzoncie czasowym
NIST oficjalnie przyznaje, że obecnie nie istnieją stuprocentowo skuteczne metody obrony przed Adversarial ML, co wymusza podejście wielowarstwowe.
Działania krótkoterminowe
· Natychmiastowe wdrożenie kontroli pochodzenia danych (Data Provenance), technik Differential Privacy oraz rygorystycznych testów na Prompt Injection.
· Każde wejście do modelu musi być traktowane jako potencjalny kod sterujący.
Działania średnioterminowe
· Implementacja Adversarial Training (uczenie na celowo zmodyfikowanych przykładach) oraz systemów monitorowania „zdrowia mentalnego” AI, zdolnych do wykrywania anomalii w warstwach ukrytych i nagłych zmian w sposobie wnioskowania.
Działania długoterminowe
· Przejście na architekturę Secure-by-Design.
· Kluczowe jest wprowadzenie cyfrowo podpisanych wag (Immutable AI Models) oraz weryfikacji sprzętowej w bezpiecznych enklawach (Secure Enclaves).
Implikacje. Skutki systemowe i społeczne
Infekcje logiczne generują konsekwencje wykraczające poza czystą technologię, uderzając w fundamenty państwa i biznesu.
Dla państwa i systemu prawnego
· Wirusy logiczne to narzędzia nowoczesnej wojny informacyjnej.
· „Zatruwanie” narodowych zasobów obliczeniowych może prowadzić do sabotażu gospodarczego na niespotykaną skalę.
· Konieczne są nowe ramy prawne regulujące odpowiedzialność za błędy algorytmiczne.
Dla Biznesu i Gospodarki
· Krytycznym zagrożeniem jest Model Stealing tj. kradzież parametrów modelu w celu eksfiltracji poufnych danych treningowych lub własności intelektualnej poprzez specyficzne zapytania konkurencji.
· Dobrym przykładem jest scenariusz „Zatrutej Dostawy”, gdzie zainfekowany model open-source aktywuje złośliwy skrypt po przetworzeniu faktury od konkretnego podmiotu, automatycznie zatwierdzając błędny przelew.
Dla społeczeństwa
· Zjawisko „algorytmicznego gaslightingu” pozwala na cichą manipulację percepcją użytkownika przez zainfekowane systemy AI, faworyzujące określone postawy lub produkty. W dobie automatyzacji jedynym bezpiecznikiem pozostaje ludzki krytycyzm i zdolność do kwestionowania wyników dostarczanych przez maszyny.
Podsumowanie
Współczesne cyberbezpieczeństwo przechodzi fundamentalną zmianę paradygmatu, ewoluując od klasycznego malware’u atakującego kod binarny w stronę „wirusów logicznych” wymierzonych w semantyczną i decyzyjną warstwę sztucznej inteligencji. Ze względu na brak ścisłej separacji między danymi a instrukcjami w sieciach neuronowych, tradycyjne systemy antywirusowe stają się bezużyteczne wobec takich zagrożeń jak Adversarial ML, Prompt Injection czy Reward Poisoning. Infiltracja ta może odbywać się poprzez subtelne manipulacje wagami modeli lub zatruwanie danych treningowych, co prowadzi do błędnego wnioskowania, eksfiltracji danych lub sabotażu systemów autonomicznych. W obliczu braku metod zapewniających pełne bezpieczeństwo, kluczowe staje się wdrożenie strategii Secure-by-Design, monitorowanie „zdrowia mentalnego” AI oraz weryfikacja łańcucha dostaw danych przed rokiem 2026.
Co to oznacza?
Oznacza to, że hakerzy nie muszą już „psuć” komputera, aby nam zaszkodzić – teraz mogą po cichu oszukać sztuczną inteligencję, by podpowiadała nam złe decyzje lub widziała rzeczywistość inaczej, niż wygląda ona naprawdę.